
NeuroZip is a task-aware neural codec for brain recordings. Instead of compressing EEG to preserve the waveform, it compresses to preserve meaning: what the person was actually looking at. At 144x compression the result is still searchable by free text, even though the model is never trained on a single word. It won 3rd place at the QBI Hackathon 2026 at UCSF, along with $1,000 and $10,000 in grants.
A collaboration with Avinash Senthil.
Why we built it
Brain-recording datasets are large, growing, and painful to store and search. The THINGS-EEG corpus was even re-released in half precision just to halve its size. Wearable EEG streams hours of data off-device on tight battery and bandwidth, and labs sit on decades of sessions where answering a question like find the trials where the subject saw a face is still a manual labeling job.
Standard compression optimizes waveform fidelity, which spends most of its bits on the loud parts of the signal. But the loud parts are not where the meaning lives. We wanted to test a different trade-off: compress to keep the decodable content, the identity of what the person saw, and throw away the rest. If that works, brain datasets get two orders of magnitude smaller and stay searchable by language at the same time.
The core idea: a frozen judge
The trick is to put a frozen judge in the loop. First we train a small projector that maps an EEG epoch to the CLIP embedding of the image the person was viewing, then freeze it. The codec is then trained so that its decompressed output still scores well under that judge, with the gradient flowing through the frozen judge back into the decoder. The same judge that decides what to keep during training is what reads your text query at inference, which is how a corpus compressed without any text becomes searchable by language.
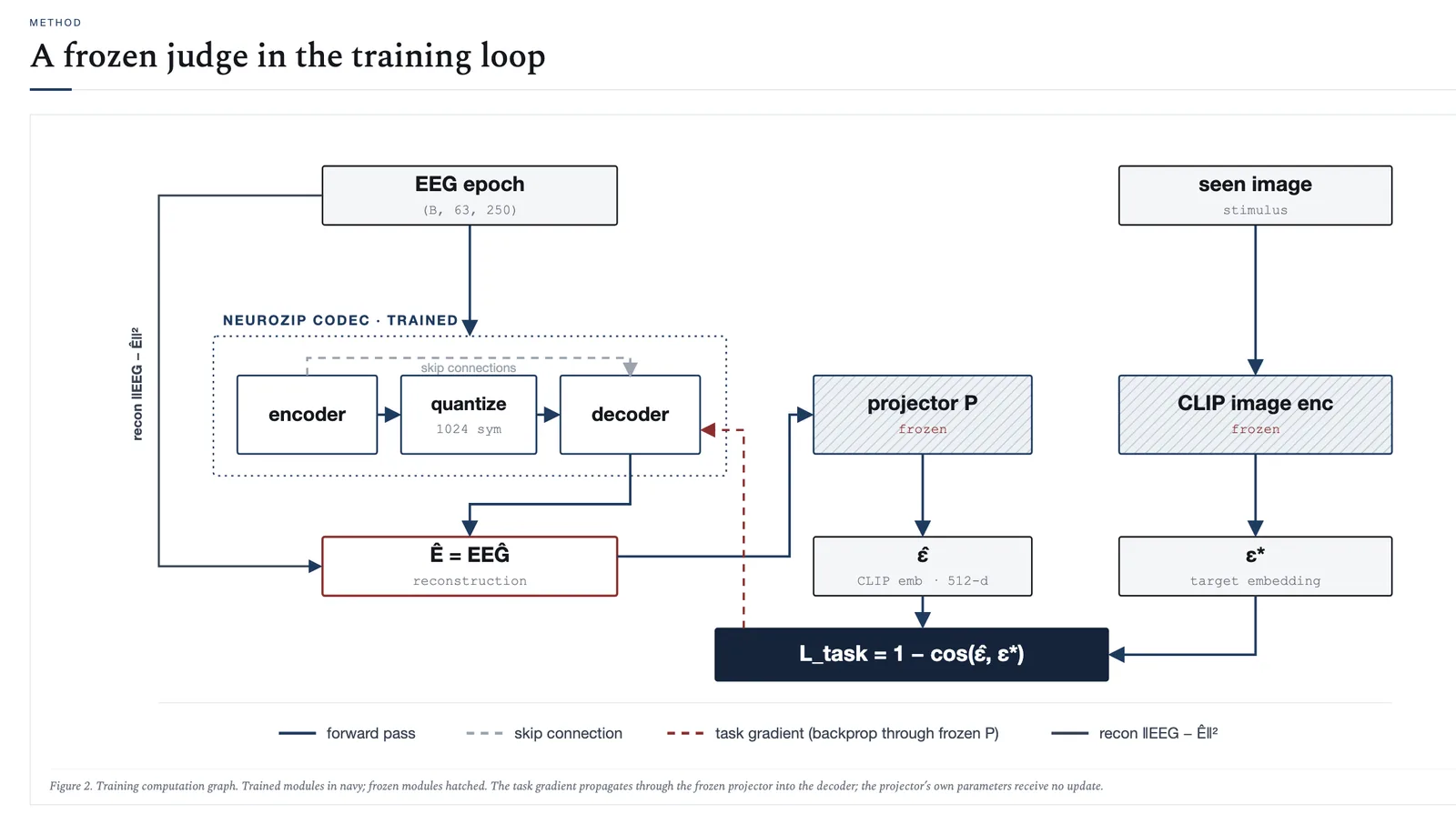
The codec is a 1D convolutional autoencoder; a frozen EEG-to-CLIP projector scores whether stimulus identity survives compression.
How it works
An epoch of shape 63 channels by 250 timesteps is encoded to a 32 by 32 grid of integer symbols, quantized, and decoded. Quantization uses additive uniform noise during training as a differentiable stand-in for rounding, and integer rounding at inference, with a factorized Laplace prior estimating the bitrate.
The objective sums three terms: a rate term that controls compression, a reconstruction term that keeps the output a valid waveform, and a task term that keeps the reconstruction decodable in CLIP space. The fidelity baseline and NeuroZip share the exact same architecture and training budget and differ only in the weight of the task term, so any difference comes from the objective, not from model capacity.
Searchable by language
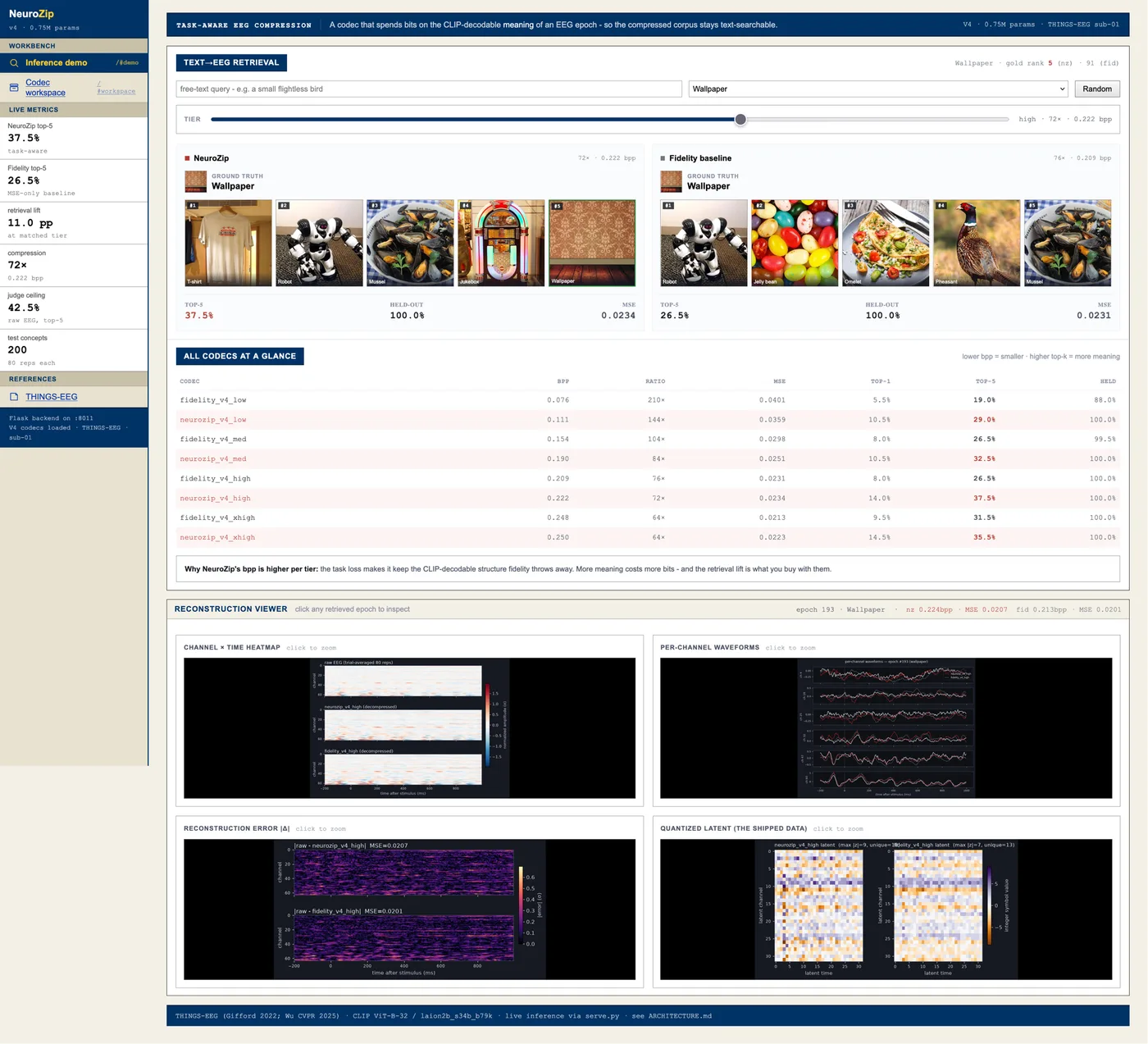
In the live demo you type a word, like ostrich, and NeuroZip returns the one-second epochs recorded while the subject was looking at an ostrich, even though it never saw text in training. Run the same query against two codecs trained on the same data: the fidelity codec loses the ostrich, and the task-aware codec keeps it. What you are searching for does not live in the loud parts of the signal that fidelity protects. It lives somewhere smaller and more fragile.
The demo: free-text to EEG retrieval with the task-aware and fidelity codecs side by side, per-tier metrics, and a reconstruction viewer.
Results
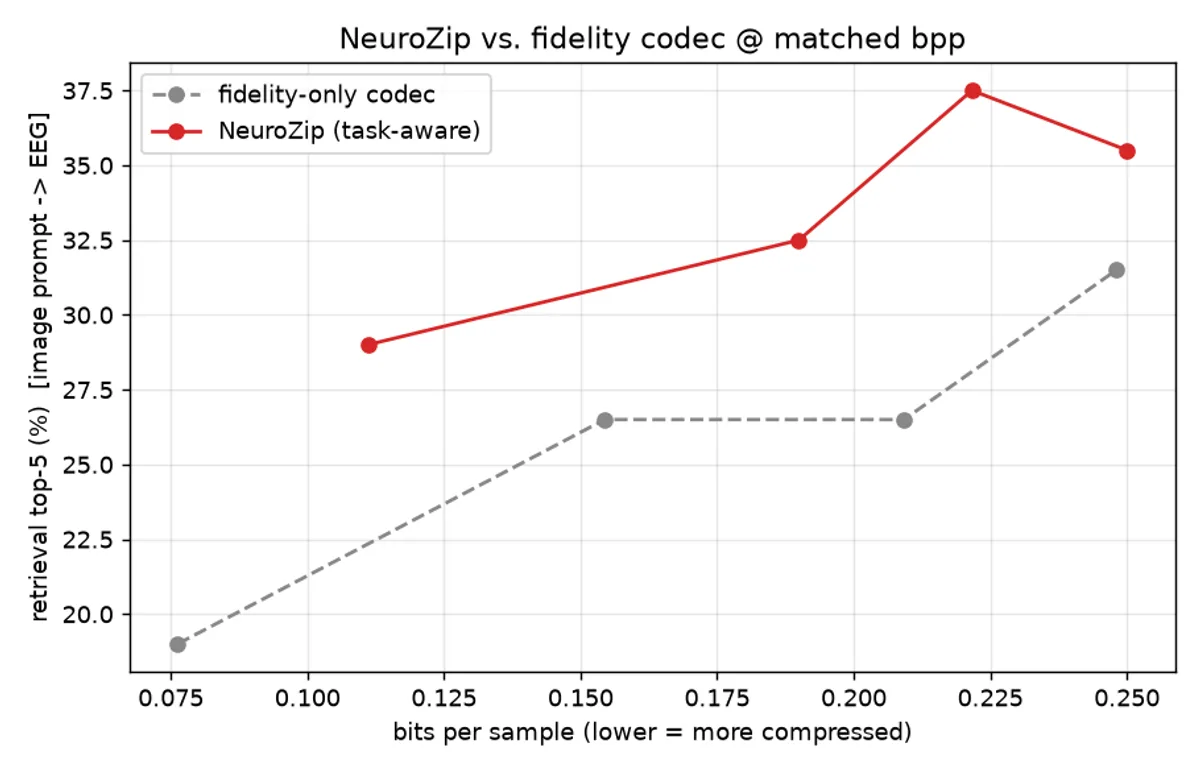
On THINGS-EEG, at matched bitrate the task-aware codec improves top-5 retrieval by 4 to 11 percentage points over the fidelity baseline, at a cost of at most 5 percent in reconstruction error. An independent classifier the codec never saw identifies the viewed object with 100 percent accuracy at 144x compression, versus 88 percent for the fidelity baseline. A corpus of a million labeled epochs drops from roughly 30 GB to about 210 MB while staying searchable.
Top-5 retrieval against bits per sample. The task-aware codec retrieves more concepts per bit at every tier.
What the compression reveals
Because the objective keeps only stimulus-decodable content, aggressive compression doubles as a tool for localizing where meaning lives in the brain. What the codec preserves tightest is the visual system: occipitotemporal electrodes reconstruct about 32 percent tighter than under fidelity, versus 7 percent on non-visual channels, a roughly 4.7 times spatial preference. In time, the N170 window from 150 to 200 milliseconds is preserved about 25 percent tighter.
Topographic maps: the preserved signal concentrates over visual cortex.
To check this was not an artifact of the metric, we shuffled the channel labels ten thousand times. Only three random sets matched the visual-set preference, p less than 0.001. This is not a neuroscience discovery, a loss supervised on object identity should preserve visual cortex. It is validation that the task gradient is shaping the codec correctly, because what it keeps matches what visual neuroscience already predicts.
Permutation test: the visual-cortex preference sits far in the tail of 10,000 random channel sets.
The hackathon
NeuroZip was built at the QBI Hackathon 2026, run by the Quantitative Biosciences Institute at UCSF, with Avinash Senthil. In a room oriented around cancer proteomics and chemical biology, an EEG project earned 3rd place, $1,000, and $10,000 in grants. The honest read is that the same method aimed at QBI-native data would place higher, and that pivot is where the work goes next.
Challenges
- Getting the gradient to flow correctly through a frozen judge. A startup assertion verifies non-zero decoder gradient from a task-only backward pass and zero projector gradient, encoding the subtle correctness condition as a runtime check.
- The architecture evolution from v1 to v4. Adding attention inside the codec quietly leaked an advantage to the fidelity baseline and muddied the comparison, so the final design reverted to a convolution-only codec with an attention-based judge.
- A subtle data gotcha: the dataset's precomputed CLIP features are LAION-2B, not OpenAI, and using the wrong variant silently breaks retrieval. Verified by cosine distance, 0.98 to the right encoder versus negative to the wrong one.
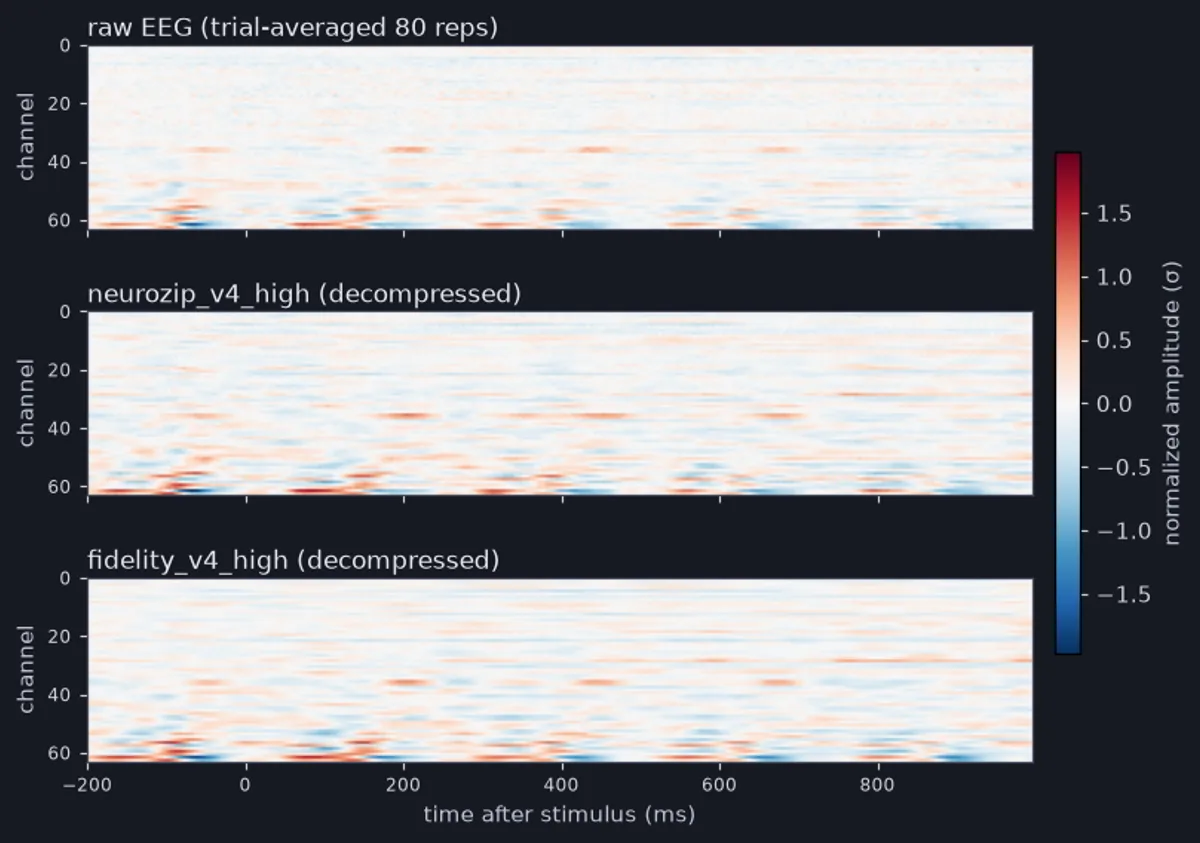
- Being honest about scope: single subject, trial-averaged over 80 repetitions. The pipeline is subject-agnostic and the codec contribution is expected to carry across subjects, but the reported numbers are for one subject.
Try it
NeuroZip is packaged as a command-line tool with Homebrew, curl, pip, and a single-file binary install. The full method, training code, results, and the THINGS-EEG dataset are documented in the repository.